This article is part of the Stata for Students series. If you are new to Stata we strongly recommend reading all the articles in the Stata Basics section.
In this section we'll take a look at two Stata data sets and see how they're put together.
Start up Stata, then type:
sysuse auto
This will load an example data set of 1978 cars that comes with Stata. Next either type:
browse
or click the button at the top that looks like a magnifying glass looking at a spreadsheet. This will open the data browser and let you look at the data set you've loaded.
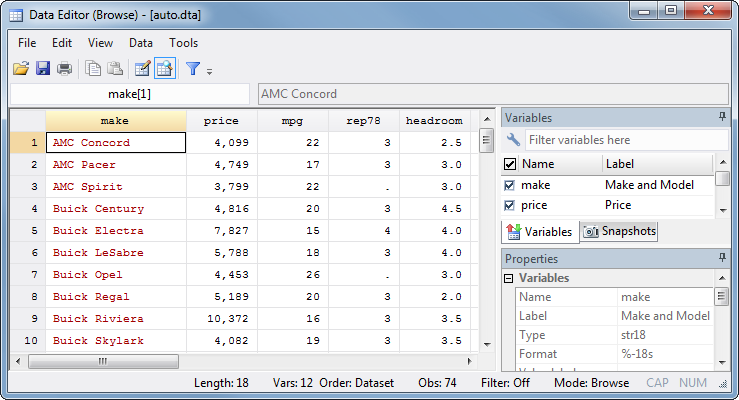 |
As you see, a Stata data set looks a lot like a spreadsheet, only more structured. The rows are always represent observations, though it's not always obvious what an "observation" is in a given data set. In this data set an observation represents a kind of car, but just looking at it you might wonder if it represented individual cars. Always be sure you know what an observation is in your data set.
The columns represent variables. There are two main kinds of variables: numbers and text (Stata generally calls text variables "strings"). In this data set the make variable is a text variable and all the others are numbers.
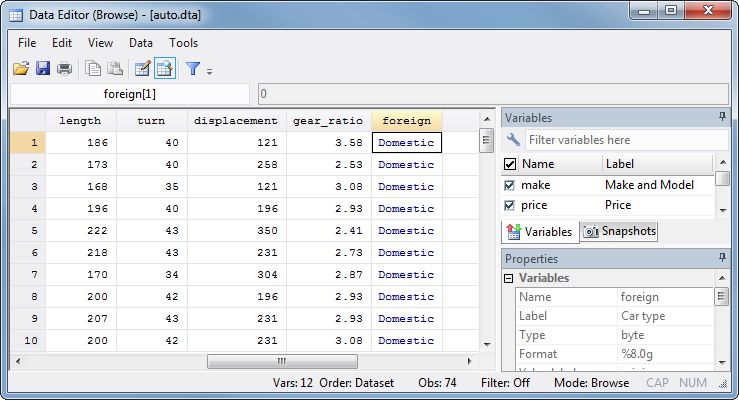
|
What about the foreign variable? (Scroll right to see it.) It looks like text, but note that the text is blue instead of red. This tells us that it is a numeric variable that has value labels associated with it. The value labels tell Stata that 0 means "Domestic" (i.e. built in the United States) and 1 means "Foreign." You'll learn how to create value labels in Creating Variables. Value labels are very useful, but they're only for your benefit: Stata commands that refer to the values of the foreign variable need to use the numbers 0 and 1, not the text "Domestic" or "Foreign."
By convention, 0 means false and 1 means true. Thus a 1 for a variable called foreign means "this car is foreign" and 0 means "this car is not foreign." If you always name binary variables after the "true" state then you almost don't need labels.
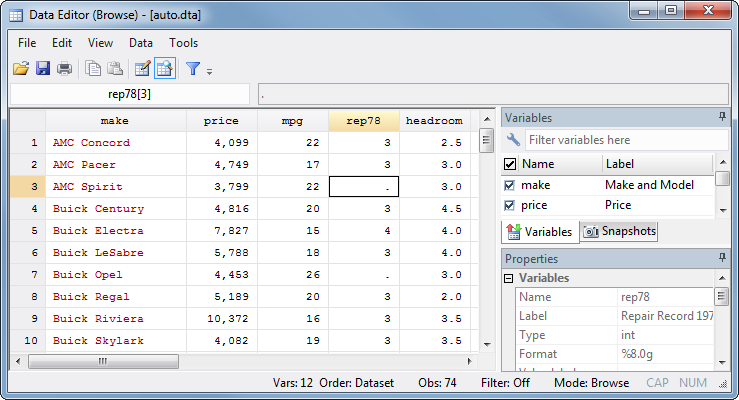
|
Next note the value of rep78 (car's repair record in 1978, on a five-point scale) for the third observation, the AMC Spirit. Repair record data weren't available for this car, so Stata stores a period, or dot, meaning that the value is missing. Surveys often need to store not just that a value is missing, but why (for example, the question didn't apply vs. the respondent refused to answer) so Stata can also use .a, .b, .c, up through .z for missing. Then data set creators can assign the different kinds of missing different meanings.
Internally, Stata stores . as a really big number and .a, .b, etc. as numbers that are even bigger than that. Just think of them all as positive infinity. That means that conditions like x>3 will be true if x is missing. On the other hand, x<. will be true for all actual values of x and false for all missing values of x, including .a through .z. You'll learn how to use conditions like this in How Stata Commands Work.
The 2014 General Social Survey
Next let's look at the 2014 General Social Survey. Close Stata. Go to the folder you created in Managing Stata Files and double-click on gss_sample.dta. Then either type browse or click on the browse button.
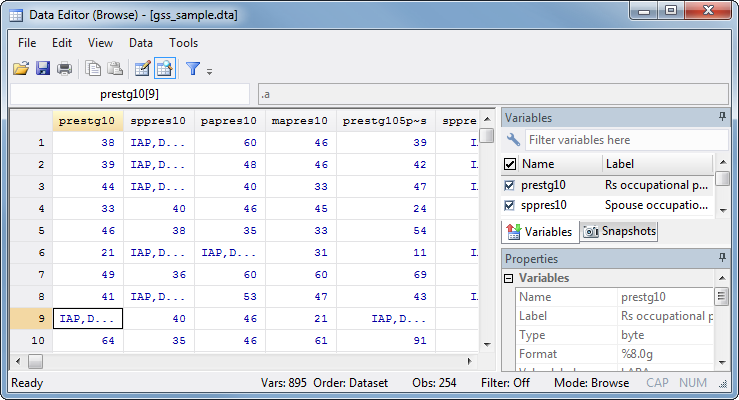
|
This is a much larger data set, in terms of both observations and variables—the Properties window in the bottom right has a Data section that will tell you just how big. Almost all the variables in this data set are in blue, meaning they have value labels. Some of these are like the value labels you saw before. For example, the sex variable has 1 labeled as "male" and 2 labeled as "female."
However, most of the value labels only label the missing values. For the prestg10 variable (respondent's occupational prestige score in 2010), the values for the first eight observations really are just the numbers you see. For observation nine, the value .a has been labeled "IAP,DK,NA" (inapplicable, don't know, or no answer). Other variables use multiple kinds of missing and assign different labels to them: for actlaw, .a is "iap", .b is "CANT CHOOSE" [sic], and .c has no label assigned. The GSS, like many real-world data sets, has some missing values for a lot of variables and a lot of missing values for some variables.
Last Revised: 6/24/2016