 Supporting Statistical Analysis for Research
Supporting Statistical Analysis for Research
4.2 Naming variables
4.2.1 Cleaning - Variable names
Data frame variable names are typically used many times when wrangling data. Good names for these variables makes it easier to write and read wrangling programs. Variable names that are easy to program with have the following properties.
Use only lower case.
Use the underscore,
_as a replacement for spaces to separate words.Clearly convey what data the variable contains.
If a word is abbreviated in a variable name, the same abbreviation is used for all names.
The use of lower case and underscores is called snake coding. There are other name coding conventions in programming such as camel coding, which uses no underscores and instead capitalizes the first letter of new words. Snake coding is commonly used by data wranglers and will be used in this book.
It is common practice to set the variable names to your desired names right after importing a data set.
4.2.2 Programming skills - Indexes
Indexes are used to identify the columns and rows of a data frame. In this section we examine the column index of a data frame.
An index value identifies a particular variable in a data frame. An index value is like the number part of a street address. The house number identifies a particular house on a street. Similarly, the column index provides a means to identify a particular variable of a data frame.
The variables that make up a data frame can be thought of
as a list.
See the figure below.
This list of variables is the column index of the data frame.
The names used for this list are the named index values.
In figure 4.1,
the names of the columns are name 1, name 2, and name k.
The names for the columns that may exists between name 2 and
name k are not given in the figure.
Using the column names is the most common, and preferred,
method for indexing variables.
The named index values of the
column index are also called the column names.
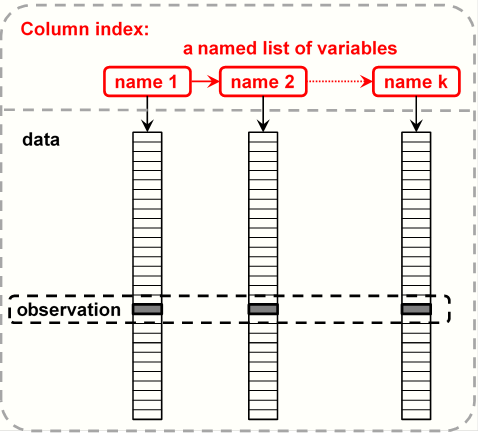
Figure 4.1: Column index of a data frame
Variables may also be indexed using a numeric position in the index list. The numeric index value of a variable is the count of its column from the left side of the data frame (start of the list.)
Consider the made up data frame from the csv example of the read csv section, displayed again here as a data frame and not a csv.
A B C D
1 51 -2 Madison
-3 1 8 Sun Prairie
9 13 VeronaThe column with the town names has a variable name of D.
The numeric index for this column
(starting the count on the left)
is either 4 if counting from 1 as in R,
or 3 if counting from 0 as in Python.
Either D or the numeric index can be used to identify this
column in the data frame.
Figure 4.1 shows that the variables of a data frame are only connected by the index. An observation (row) is made up of the values in the same row of each of these variables.
4.2.3 Examples - R
R counts objects starting at 1. As such, the first column or row will have a numeric index value of 1. The numeric index value increases by 1 for each of the remaining columns.
These examples use the airAccs.csv data set. It is a record of air accidents.
We begin by loading the tidyverse and then importing the csv file.
library(tidyverse)airAccs_path <- file.path("..", "datasets", "airAccs.csv") air_accidents <- read_csv(airAccs_path, col_types = cols())Warning: Missing column names filled in: 'X1' [1]glimpse(air_accidents)Observations: 5,666 Variables: 8 $ X1 <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1... $ Date <date> 1908-09-17, 1912-07-12, 1913-08-06, 1913-09-09, 191... $ location <chr> "Fort Myer, Virginia", "Atlantic City, New Jersey", ... $ operator <chr> "Military - U.S. Army", "Military - U.S. Navy", "Pri... $ planeType <chr> "Wright Flyer III", "Dirigible", "Curtiss seaplane",... $ Dead <dbl> 1, 5, 1, 14, 30, 21, 19, 20, 22, 19, 27, 20, 20, 23,... $ Aboard <dbl> 2, 5, 1, 20, 30, 41, 19, 20, 22, 19, 28, 20, 20, 23,... $ Ground <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
4.2.3.1 Cleaning - Variable names
Viewing the column names of the data frame.
The column names are seen in the
glimpse()display. The column names can also be displayed using the R functioncolnames().colnames(air_accidents)[1] "X1" "Date" "location" "operator" "planeType" "Dead" [7] "Aboard" "Ground"The airAccs data set has variable names for all but the first variable. The variable names have an inconsistent use of capitalization and do not use our preferred underscore naming.
We will rename the variables using snake coding with the
rename()method. The first rename parameter is the data frame to be used. The next parameters use the new variable name as the parameter name and the old variable name as the parameter value, such asnew = old. This example uses named column index values to rename the variables.air_accidents <- rename( air_accidents, date = Date, plane_type = planeType, dead = Dead, aboard = Aboard, ground = Ground ) glimpse(air_accidents)Observations: 5,666 Variables: 8 $ X1 <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, ... $ date <date> 1908-09-17, 1912-07-12, 1913-08-06, 1913-09-09, 19... $ location <chr> "Fort Myer, Virginia", "Atlantic City, New Jersey",... $ operator <chr> "Military - U.S. Army", "Military - U.S. Navy", "Pr... $ plane_type <chr> "Wright Flyer III", "Dirigible", "Curtiss seaplane"... $ dead <dbl> 1, 5, 1, 14, 30, 21, 19, 20, 22, 19, 27, 20, 20, 23... $ aboard <dbl> 2, 5, 1, 20, 30, 41, 19, 20, 22, 19, 28, 20, 20, 23... $ ground <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...Note, the parameters were written on individual lines to enhance the readability of the code.
Using numbered indexes.
Numbered indexes can also be used in the
rename()function. We repeat the prior example adding a numeric index value for the first variable which had no name in the data set.air_accidents <- read_csv(airAccs_path, col_types = cols()) air_accidents <- rename( air_accidents, obs_num = 1, date = Date, plane_type = planeType, dead = Dead, aboard = Aboard, ground = Ground ) glimpse(air_accidents)Observations: 5,666 Variables: 8 $ obs_num <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, ... $ date <date> 1908-09-17, 1912-07-12, 1913-08-06, 1913-09-09, 19... $ location <chr> "Fort Myer, Virginia", "Atlantic City, New Jersey",... $ operator <chr> "Military - U.S. Army", "Military - U.S. Navy", "Pr... $ plane_type <chr> "Wright Flyer III", "Dirigible", "Curtiss seaplane"... $ dead <dbl> 1, 5, 1, 14, 30, 21, 19, 20, 22, 19, 27, 20, 20, 23... $ aboard <dbl> 2, 5, 1, 20, 30, 41, 19, 20, 22, 19, 28, 20, 20, 23... $ ground <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...Note, output from
read_csv()was not displayed.
4.2.4 Examples - Python
Python counts objects starting at 0. So the first column will have a numeric index value of 0. The numeric index value is 1 larger for each of the remaining columns. The numeric index value for the last column will be one less than the number of columns.
These examples use the airAccs.csv data set. It is a record of air accidents.
We begin by loading the pandas and os package and then importing the csv file.
from pathlib import Path import pandas as pdairAccs_path = Path('..') / 'datasets' / 'airAccs.csv' air_accidents = pd.read_csv(airAccs_path) print(air_accidents.dtypes)Unnamed: 0 int64 Date object location object operator object planeType object Dead float64 Aboard float64 Ground float64 dtype: object
4.2.4.1 Cleaning - Variable names
Viewing the column names of the data frame.
The column names are seen in the
dtypesdisplay above. The column names can also be displayed using thecolumnsattribute of a data frame.print(air_accidents.columns)Index(['Unnamed: 0', 'Date', 'location', 'operator', 'planeType', 'Dead', 'Aboard', 'Ground'], dtype='object')The names of the column index can be returned using the values attribute of the data frame index object.
air_accidents_columns = air_accidents.columns print(air_accidents_columns.values)['Unnamed: 0' 'Date' 'location' 'operator' 'planeType' 'Dead' 'Aboard' 'Ground']The airAccs data set has variable names for all but the first variable. The first variable was given the name
Unnamed: 0by pandas. The variable names have an inconsistent use of capitalization and do not use our preferred underscore naming.We will rename the variables using snake coding with the
rename()method. The columns parameter uses a mapping of the old name (left of the colon) to new names (right side of colon,) such asold: new.The mapping for the variable name changes is easier to read when the map for each changed variable is on a separate line. When there are too many parameters to a function or method to fit on a single line, they can also be written with a parameter per line.
air_accidents = air_accidents.rename( columns={ 'Unnamed: 0': 'obs_num', 'Date': 'date', 'planeType': 'plane_type', 'Dead': 'dead', 'Aboard': 'aboard', 'Ground': 'ground'}) print(air_accidents.dtypes)obs_num int64 date object location object operator object plane_type object dead float64 aboard float64 ground float64 dtype: objectNote, Python index names should not use any Python reserved word. This could cause syntax errors later when you use those names.
Using numbered indexes.
Numbered indexes cannot be used directly in the name mapping of the
columnsparameter. To access the first position, we need to use the column method and ask for the first column name. (Remember that Python numbering starts at 0.) We repeat the prior example usingair_accidents_columns.values[0]to identify the first variable which had no name in the data set.air_accidents = pd.read_csv(airAccs_path) air_accidents = air_accidents.rename( columns={ air_accidents_columns.values[0]: 'obs_num', 'Date': 'date', 'planeType': 'plane_type', 'Dead': 'dead', 'Aboard': 'aboard', 'Ground': 'ground'}) print(air_accidents.dtypes)obs_num int64 date object location object operator object plane_type object dead float64 aboard float64 ground float64 dtype: object
4.2.5 Exercises
These exercises use the PSID.csv data set.
Import the
PSID.csvdata set.Set the variable names to something useful, if they are not already. Change at least one name.