 Supporting Statistical Analysis for Research
Supporting Statistical Analysis for Research
3.3 Data frames
A data frame in the tidyverse is called a tibble. A tibble contains a set of columns, that are called variables. The data of a data frame are located in these variables. The variables of a data frame are organized by an index. The index provides the order of the variables and any names that are given to the variables. The preferred method of referencing the variables of a data frame Is by their names.
A tibble can be thought of as a list variables.
This list of variables is the column index of the data frame.
See the figure below.
In this figure, name 1, name 2, and name k are the column names
contained in the index.
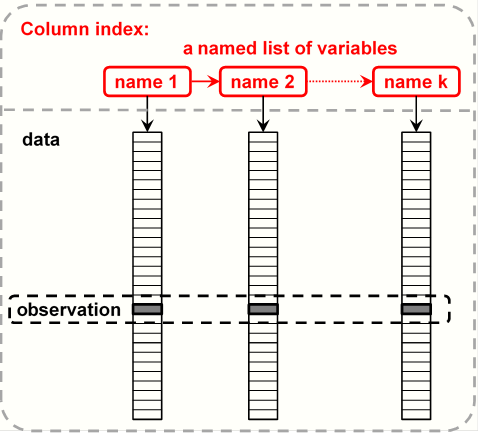
Figure 3.1: Column index of a data frame
The figure above shows that the variables of a data frame
are only connected by the index.
An observation (row) is made up of the values in the
same row of the variables of the tibble.
A data frame can be imported from a variety of sources,
delimited file, excel, SQL, etc.
The tidyverse has readers for the common types of data files.
These reader all share a common set of parsers,
a function that formats the data of a variable.
This chapter will focus on reading .csv files,
a form of delimited files.
Example
Importing a
.csvfile.forbes_in <- read_csv( file.path("..", "datasets", "Forbes2000.csv"), col_types = cols() )Warning: Missing column names filled in: 'X1' [1]glimpse(forbes_in)Observations: 2,000 Variables: 9 $ X1 <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ rank <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ name <chr> "Citigroup", "General Electric", "American Intl Gr... $ country <chr> "United States", "United States", "United States",... $ category <chr> "Banking", "Conglomerates", "Insurance", "Oil & ga... $ sales <dbl> 94.71, 134.19, 76.66, 222.88, 232.57, 49.01, 44.33... $ profits <dbl> 17.85, 15.59, 6.46, 20.96, 10.27, 10.81, 6.66, 7.9... $ assets <dbl> 1264.03, 626.93, 647.66, 166.99, 177.57, 736.45, 7... $ marketvalue <dbl> 255.30, 328.54, 194.87, 277.02, 173.54, 117.55, 17...The
col_typeparameter is used to define which parser will be used for each variable in the the data frame. Usingcols()as the value forcol_typetells the tidyverse to use its best guess for the type. This is useful for explority work with a data set that is not well defined. For production code, you should define the type for each variable in thecol_typesparameter.