 Supporting Statistical Analysis for Research
Supporting Statistical Analysis for Research
5.6 Related observations
These exercises use the mtcars.csv data set.
Import the
mtcars.csvdata set.from pathlib import Path import pandas as pd import numpy as npmtcars_path = Path('..') / 'datasets' / 'mtcars.csv' mtcars_in = pd.read_csv(mtcars_path) mtcars_in = mtcars_in.rename(columns={'Unnamed: 0': 'make_model'}) mtcars = mtcars_in.copy(deep=True) print(mtcars.dtypes)make_model object mpg float64 cyl int64 disp float64 hp int64 drat float64 wt float64 qsec float64 vs int64 am int64 gear int64 carb int64 dtype: objectFind the most efficient car (mpg) for each number of cylinders.
best_mpg_cyl = ( mtcars .assign(mpg_rank = lambda df: df .groupby('cyl') ['mpg'] .rank(method='min', ascending=False))) (best_mpg_cyl .query('mpg_rank == 1') .loc[:, ['make_model', 'cyl', 'mpg', 'disp']] .head() .pipe(print))make_model cyl mpg disp 3 Hornet 4 Drive 6 21.4 258.0 19 Toyota Corolla 4 33.9 71.1 24 Pontiac Firebird 8 19.2 400.0The weight of a car is a major contributor to how efficient it is. Create a variable that measures mpg per unit of weight. Plot this new variable against
hpand thendisp, These plots should consider the relationship with the number of cylinders. From these plots, doeshpordispseem to be more related to the new variable when considering the number of cylinders?mtcars = ( mtcars .assign(mpg_per_wt = lambda df: df['mpg'] / df['wt'])) (mtcars .loc[:, ['make_model', 'wt', 'mpg', 'mpg_per_wt']] .head() .pipe(print))make_model wt mpg mpg_per_wt 0 Mazda RX4 2.620 21.0 8.015267 1 Mazda RX4 Wag 2.875 21.0 7.304348 2 Datsun 710 2.320 22.8 9.827586 3 Hornet 4 Drive 3.215 21.4 6.656299 4 Hornet Sportabout 3.440 18.7 5.436047print( p9.ggplot(mtcars, p9.aes(x='disp', y='mpg_per_wt')) + p9.geom_point() + p9.facet_wrap('~cyl') + p9.theme_bw())<ggplot: (-9223371893261961419)>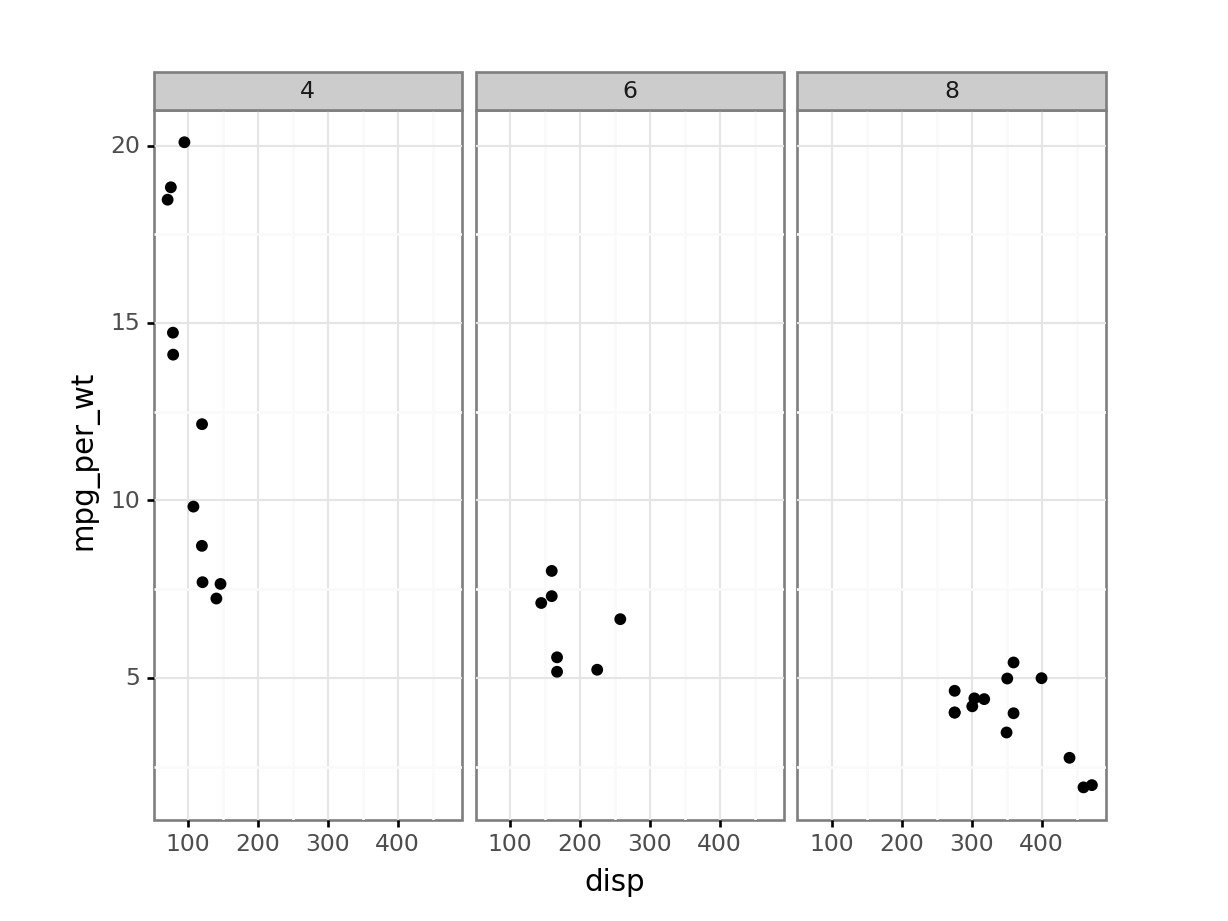
print( p9.ggplot(mtcars, p9.aes(x='hp', y='mpg_per_wt')) + p9.geom_point() + p9.facet_wrap('~cyl') + p9.theme_bw())<ggplot: (-9223371893262604358)>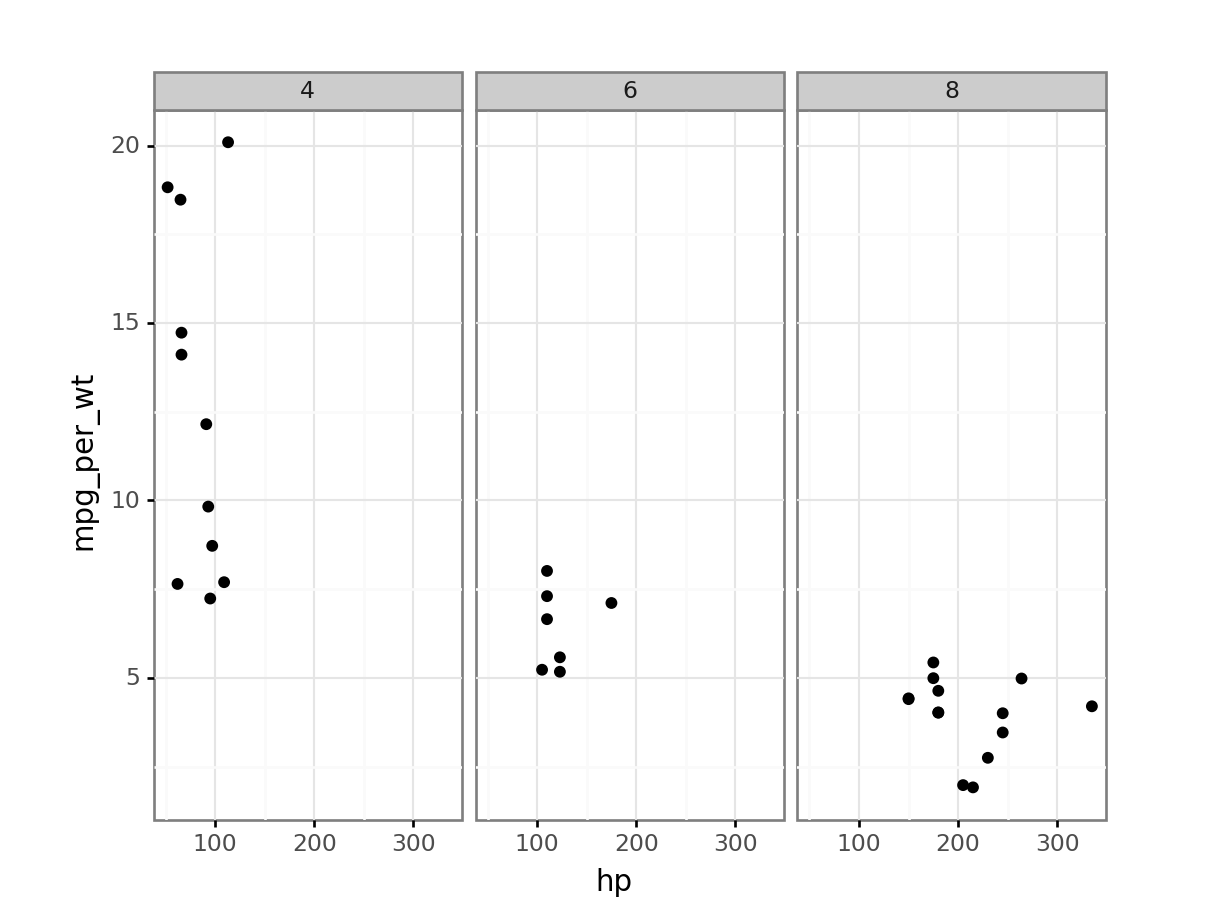
Both
hpanddispseem to be related tompg_per_wt. Thedispvariable seems to have a stronger relationship withmpg_per_wt.Find the least efficient car (using the new variable that considers both mpg and weight) for each number of cylinders and gear combination. Exclude any combination that does not have at least two observations.
eff_cyl_gear = ( mtcars .assign( num_group_obs = lambda df: df .groupby(['cyl', 'gear']) ['mpg_per_wt'] .transform('size'), efficiency_rank = lambda df: df .groupby(['cyl', 'gear']) ['mpg_per_wt'] .rank(method='min', ascending=True)) .query('num_group_obs >= 2 & efficiency_rank == 1')) (eff_cyl_gear .loc[:, ['make_model', 'cyl', 'gear', 'mpg_per_wt', 'mpg', 'disp']] .sort_values(['cyl', 'gear', 'mpg_per_wt']) .head(5) .pipe(print))make_model cyl gear mpg_per_wt mpg disp 8 Merc 230 4 4 7.238095 22.8 140.8 26 Porsche 914-2 4 5 12.149533 26.0 120.3 5 Valiant 6 3 5.231214 18.1 225.0 10 Merc 280C 6 4 5.174419 17.8 167.6 15 Lincoln Continental 8 3 1.917404 10.4 460.0